180727 프로젝트 회의
in Data on 패스트캠퍼스-프로젝트
18.07.27 프로젝트 회의
목적
롤 좀 올라가보자아아아아!!!
ver 1
로딩 단계에서 매칭된 상대팀의 데이터를 가져와서 자신의 데이터와 단순 비교
시야, 획득 골드, k/d/a, 아이템 비교한다
ver 2
각 등급별(브론즈/실버/골드/다이아/플랜티넘/마스터/챌린지) 데이터를 가져와서 등급별 통계를 만든다.
사용 기술 스택 정리
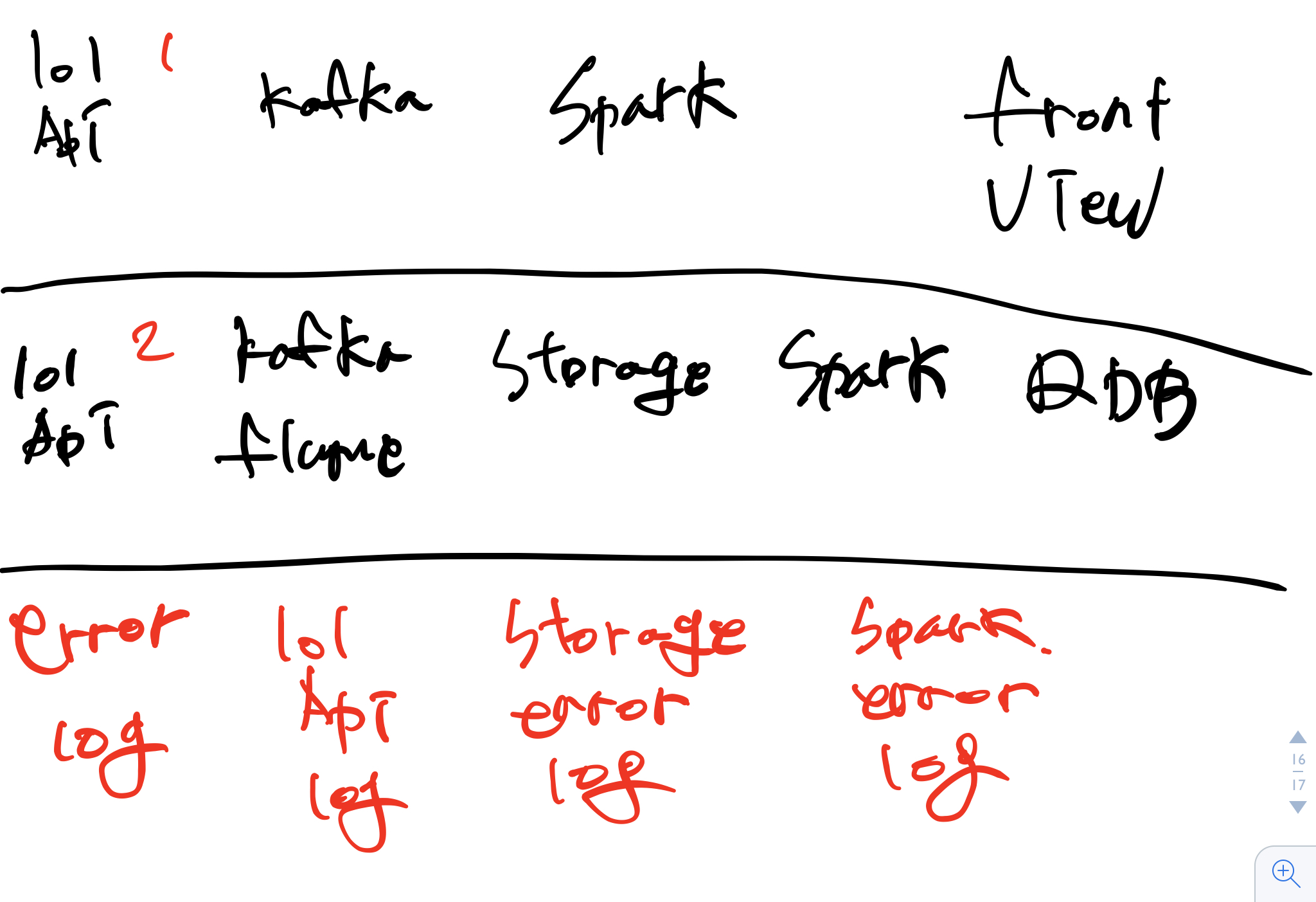
apache kafka
Apache Kafka(아파치 카프카)는 LinkedIn에서 개발된 분산 메시징 시스템으로써 2011년에 오픈소스로 공개되었다. 대용량의 실시간 로그처리에 특화된 아키텍처 설계를 통하여 기존 메시징 시스템보다 우수한 TPS를 보여주고 있다.
Kafka는 발행-구독(publish-subscribe) 모델을 기반으로 동작하며 크게 producer, consumer, broker로 구성된다.
kafka 와 flume 을 사용하여 데이터 수집 하려한다
apache flume
data 수집기
hadoop 에 붙이기 용이함
kafka 와 유사하여 요즘은 ( kafka + flume )으로 사용한다.
사용하는 이유는 롤 api 를 무제한 호출 할 수 없기에 여러 머신(aws)에서 나눠서 데이터를 가져오려고 한다. 여러 머신(aws)에서 가져온 데이터를 kafka로 모으려 한다
var type;
type =
aws (s3)
데이터 저장소로 사용하려고 한다
hdfs(aws_ec2 or local)
로그 데이터 및 사용자의 통계 데이터
apache spark(zeppelin)
이걸 왜 쓰냐고 묻는 바보같은 놈은 없겠지
앞에서 kafka+flume 으로 가져온 데이터를 분석 한다
rdb
ver2 에 사용할 부분
사용자의 분석된 데이터는 rdb 에 넣기로 했다.
등록되어 있지 않은 사용자라면 lol api 를 통해 분석을 하고 기 등록된 사용자라면 기존 데이터를 가져와서 뿌려주고 최신 데이터가 아니면 이때 갱신요청을 받는다
